Russ Mayne wrote an interesting post a few days ago on the constructions “my wife and I” and “me and my wife”. I fully agree with him regarding the ‘correctness’ of either construction and the main thrust of his post, but I did have a thought about one very specific part of his post.
Here is the pertinent part of Russ’ post:
The words ‘Me and my wife’ are in the subject position (at the start of the sentence) and so we should use the subject pronoun ‘I’
English sentences usually start with subjects. so in ‘I love you’, I is the subject. If it were the object it would change to ‘me’ such as ‘you love me’. The sentence ‘me and my wife went to the party’ seems to flaunt this rule because ‘me’ is in the subject position and so it should be I.
The problem with this argument is, were it true, the sentence ‘I and my wife went to the party’ would be a perfectly proper sentence, after all, the subject is properly ‘I’. However, ‘I and my wife’ sounds a bit off to me. So is something else is going on here?
McWhorter makes the rather bold claim that ‘me’, not ‘I’ is in fact English’s subject pronoun and that I is a rather special word that is only used when there is only one subject before the verb. Therefore ‘I went to the party’ sounds OK, and ‘me and the lads went to the party’ sounds OK, but ‘I and the lads went to the party’ doesn’t sound right because there is more than one subject. I’d never heard this argument before but I’d welcome some disconfirming evidence.
I’m not going to claim that I have disconfirming evidence, but I would like to express my skepticism and suggest that frequency effects are playing a large role (there’s also an element in play here that pronouns are more slippery than many people realize).
I also find that the construction “I and my wife” sounds a bit off. However, I doubt the notion of “I is a rather special word that is only used when there is only one subject before the verb”. Rather, because I encounter “me” used in these constructions much more frequently than “I”, that is the construction that sounds right to me.
Here is a bit of data from the BNC:

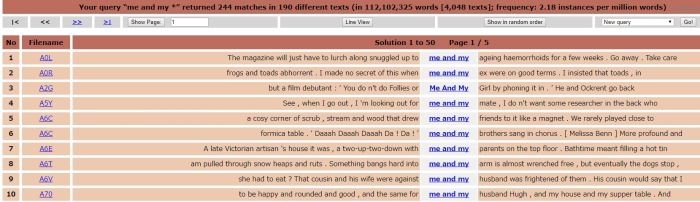

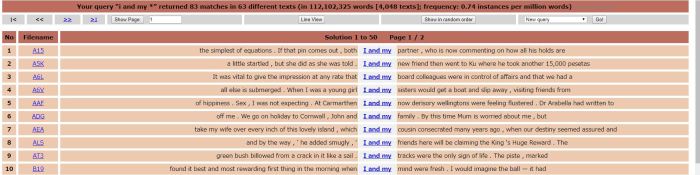
Looking at these lines, “me and my wife” is more frequent than “I and my wife”, though only a relatively small sample was found (7:3). The open “me and my *” was more frequent than “I and my *”. In this case the ratio is 244:83. To me, those 83 occurrences of “I and my *” are interesting. The construction is in use. Is the sample large enough (are enough people using it) to assume these aren’t simply mistakes or production errors? I think for the moment it is. Presumably, the people using the construction don’t find anything about it that sounds wrong, or feel a need to stop and rephrase. And, as odd as it sounds to me, I don’t really think there is anything wrong with it.
A few years ago in Slate, Gretchen McCulloch wrote:
Your sense of English as a whole is really an abstract combination of all of the idiolects that you’ve experienced over the course of your life, especially at a young and formative age. The conversations you’ve had, the books you’ve read, the television you’ve watched: all of these give you a sense of what exists out there as possible variants on the English language. The elements that you hear more commonly, or the features that you prefer for whatever reason, are the ones you latch onto as prototypical.
I think that my preference for “me and my *” over “I and my *” isn’t rooted in anything inherent about the subjective/objective properties of I/me, but stems from the frequency of my encounters (including my own production) with the construction(s). In other words, I doubt that there is a binary I=sub. pronoun and me=obj. pronoun (or vice versa) quality at work here, but that either pronoun can be sub/obj depending on context, and that my idiolect (more specifically for the matter at hand, my internal grammar about which construction is preferred in certain situations) is influenced, if not driven, by frequency effects of usage.
In summary: I prefer “me and my *”. But the corpus data shows that some other people use “I and my *”. I think that both are grammatical and that the preference for one or the other is largely a product of frequency effects on the idiolect. That is, frequency of exposure affects whether something ‘sounds right’.
(One more complicating factor: I don’t know enough about phonology to be sure, but I wouldn’t be surprised if the majority preference for “me and my *” had a phonological aspect, too. Something along the lines of a preference for duplicating the intial “m” or avoiding the rhyme of “I and my”. Then again, I might just be showcasing my idiolectal preference for both of those things 😉 )